
 The Conversation
The Conversation
From the earliest year of school, children begin learning how to express ideas in different ways. Lines across a page, a wobbly letter, or a simple drawing form the foundation for how we share meaning beyond spoken language.
Over time, those first marks evolve into complex ideas. Children learn to combine words with visuals, express abstract concepts, and recognise how images, symbols and design carry meaning in different situations.
But generative artificial intelligence (AI), software that creates content based on user prompts, is reshaping these fundamental skills. AI is changing how people create, edit and present both text and images. In other words, it changes how we see – and how we decide what’s real.
Take photos, for example. They were once seen as a “mirror” of reality. Now, more people recognise their constructed nature.
Similarly, generative AI is disrupting long-held assumptions about the authenticity of images. These can appear photorealistic but can depict things or events that never existed.
Our latest research, published in the Journal of Visual Literacy, identifies key literacies at each stage of the AI image generation process, from selecting an AI image generator to creating and refining content.
As the way people make images changes, knowing how generative AI works will let you better understand and critically assess its outputs.
Textual and visual literacy
Literacy today extends beyond reading and writing. The Australian Curriculum defines literacy as the ability to “use language confidently for learning and communicating in and out of school”. The European Union broadens this to include navigating visual, audio and digital materials. These are essential skills not only in school, but for active citizenship.
These abilities span making meaning, communicating and creating through words, visuals and other forms. These abilities also require adapting expression to different audiences. You might text a friend informally but email a public official with more care, for example. Computers, too, demand different forms of literacy.
In the 1960s, users interacted with computers through written commands. By the 1970s, graphical elements like icons and menus emerged, making interaction more visual.
Generative AI is often a mix between these two approaches. Some technologies, like ChatGPT, rely on text prompts. Others, like Adobe’s Firefly, use both text commands and button controls.
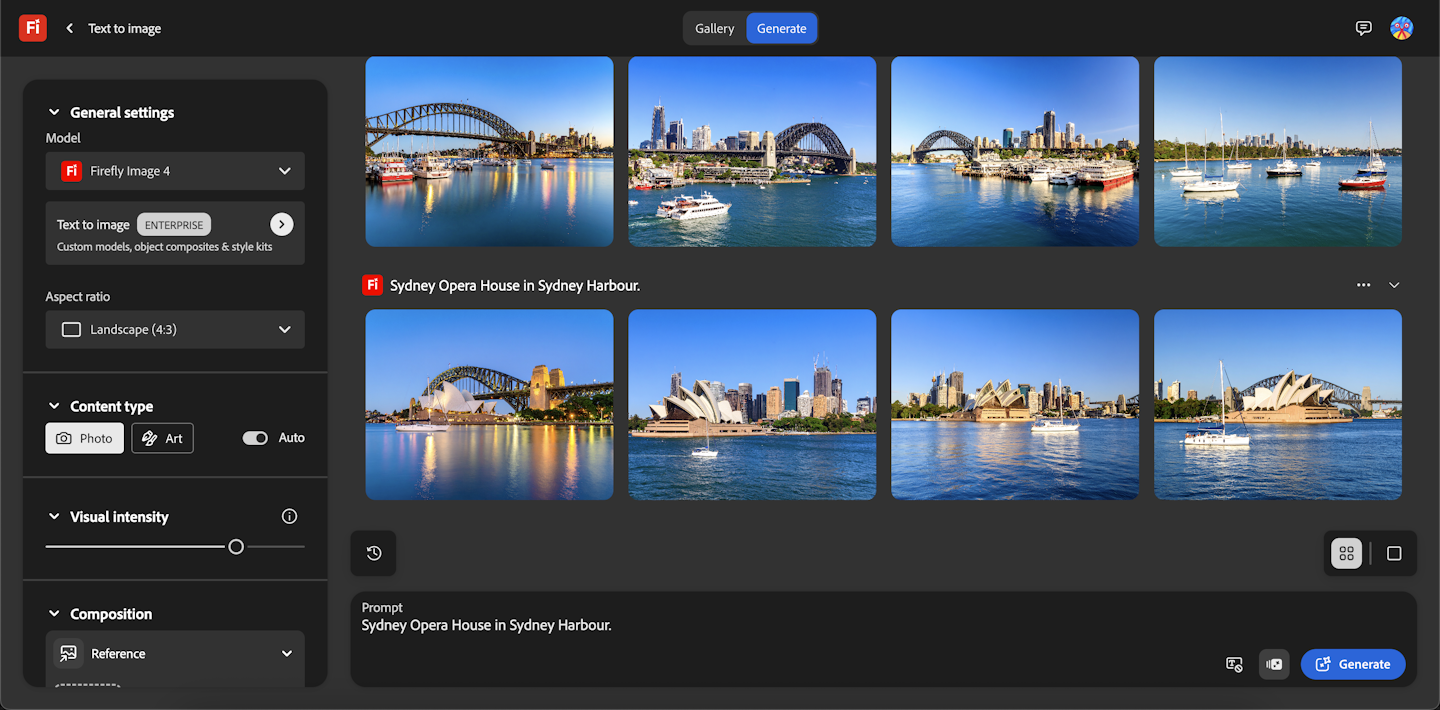
Software often interprets or guesses user intent. This is especially true for minimalistic prompts, such as a single word or even an emoji. When these are used for prompts, the AI system often returns a stereotypical representation based on its training data or the way it’s been programmed.
Being more specific in your prompt helps to arrive at a result more aligned with what you envisioned. This highlights that we need “multimodal” literacies: knowledge and skills that cut across writing and visual modes.
What are some key literacies in AI generation?
One of the first generative AI literacies is knowing which system to use.
Some are free. Others are paid. Some might be free but built on unethical datasets. Some have been trained on particular datasets that make the outputs more representative or less risky from a copyright infringement perspective. Some support a wider range of inputs, including images, documents, spreadsheets and other files. Others might support text-only inputs.
After selecting an image generator, you need to be able to work with it productively.
If you’re trying to make a square image for an Instagram post, you’re in luck. This is because many AI systems produce images with a square orientation by default. But what if you need a horizontal or vertical image? You’ll have to ask for that or know how to modify that setting.
What if you want text included in your image? AI still struggles with rendering text, similarly to how early AI systems struggled with accurately representing human fingers and ears. In these cases, you might be better off adding text in a different software, such as Canva or Adobe InDesign.
Many AI systems also create images that lack specific cultural context. This lets them be easily used in wider contexts. Yet it might decrease the emotional appeal or engagement among audiences who perceive these images as inauthentic.
Working with AI is a moving target
Learning AI means keeping pace with constant change. New generative AI products appear regularly, while existing platforms rapidly evolve.
Earlier this year, OpenAI integrated image generation into ChatGPT and TikTok launched its AI Alive tool to animate photos. Meanwhile, Google’s Veo 3 made cinematic video with sound accessible to Canva users, and Midjourney introduced video outputs.
These examples show where things are headed. Users will be able to create and edit text, images, sound and video in one place rather than having to use separate tools for each.
Building multimodal literacies means developing the skills to adapt, evaluate and co-create as technology evolves.
If you want to start building those literacies now, begin with a few simple questions.
What do I want my audience to see or understand? Should I use AI for creating this content? What is the AI tool producing and how can I shape the outcome?
Approaching visual generative AI with curiosity, but also critical thinking is the first step toward having the skills to use these technologies intentionally and effectively. Doing so can help us tell visual stories that carry human rather than machine values.
This article is republished from The Conversation, a nonprofit, independent news organization bringing you facts and trustworthy analysis to help you make sense of our complex world. It was written by: T.J. Thomson, RMIT University; Daniel Pfurtscheller, University of Innsbruck; Katharina Christ, National Institute for Science Communication; Katharina Lobinger, Università della Svizzera italiana, and Nataliia Laba, University of Groningen
Read more:
- Why we should be skeptical of the hasty global push to test 15-year-olds’ AI literacy in 2029
- AI in the classroom is hard to detect – time to bring back oral tests
- AI poses risks to national security, elections and healthcare. Here’s how to reduce them
T.J. Thomson receives funding from the Australian Research Council. He is an affiliate with the ARC Centre of Excellence for Automated Decision Making & Society.
Daniel Pfurtscheller previously received funding from the Tyrolean Science Fund and the Austrian Science Fund, for research unrelated to this article.
Katharina Christ works in a project funded by the Klaus Tschira Foundation. This research is unrelated to the content of this article.
Katharina Lobinger has previously received funding from the Swiss National Science Foundation and the Federal Office of Communications in Switzerland.
Nataliia Laba has previously received Research Training Program funding from the Australian Government Department of Education.


 PBS NewsHour World
PBS NewsHour World The Daily Beast
The Daily Beast KPTV Fox 12 Oregon
KPTV Fox 12 Oregon Mediaite
Mediaite NHL
NHL The Shaw Local News Sports
The Shaw Local News Sports Raw Story
Raw Story MLB
MLB